BMVC 2025 - Back To The Drawing Board:
Rethinking Scene-Level Sketch-Based Image Retrieval
In the era of massive multimedia archives, finding the exact visual information you need is a major challenge. While text-based retrieval is simple and intuitive, it often fails to capture complex spatial layouts or fine-grained visual attributes.
Scene-Level Sketch-Based Image Retrieval
Sketch-Based Image Retrieval (SBIR) offers a powerful alternative, letting you search with a direct visual language. Our research tackles the difficult case of Scene-level SBIR—retrieving entire complex scenes based on abstract, freehand sketches.
Our Approach
Instead of complex new architectures, we went back to the drawing board, revealing the untapped potential in simple design choices: pre-training, model architecture, and training loss.
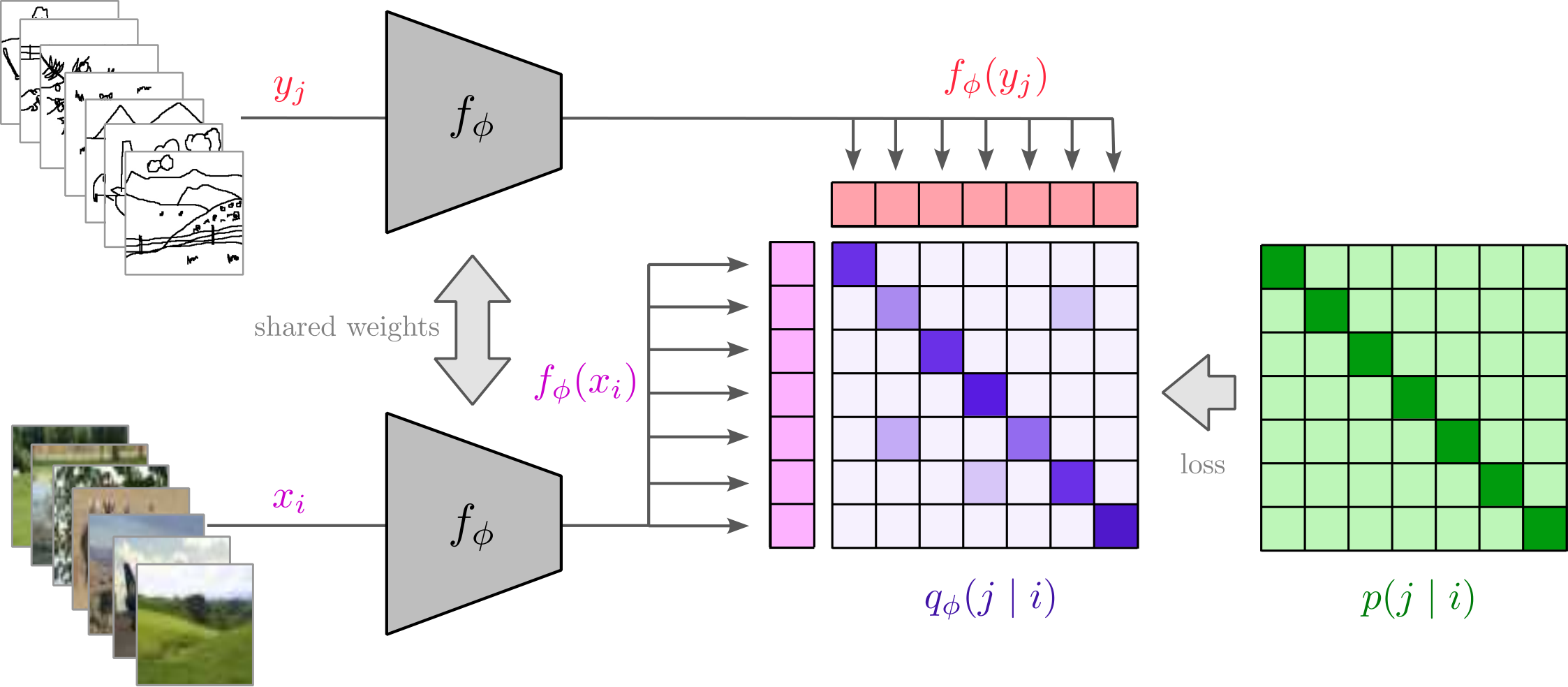
Siamese encoder architecture with ConvNeXt backbone
Key Insights
Our method is driven by two insights:
- The datasets are small and diverse, making models prone to overfitting
- Sketches are inherently imprecise, demanding robustness to ambiguity and noise
Architecture
We use a Siamese encoder architecture that projects both sketches and images into a single, aligned embedding space. This is vital for cross-modal alignment, especially with limited training samples, where heterogeneous encoders often overfit.
For the encoder, we chose ConvNeXt, pretrained as the visual encoder of a CLIP-based model. This approach provides significantly better generalization capabilities compared to variants pretrained only on ImageNet.
Training Loss
We designed a training loss that is explicitly robust to sketch ambiguity. We implemented the ICon loss, which introduces an explicit debiasing mechanism. This mechanism down-weights misleading negatives in the batch, effectively tolerating the inherent uncertainty of a sketch that might semantically align with multiple images.
Results
The results confirm the power of this simple yet effective approach. On the challenging FS-COCO dataset, comprising 10,000 MS-COCO images paired with realistic freehand scene sketches, our method achieves state-of-the-art performance.
| Method | R@1 (Normal) | R@5 (Normal) | R@10 (Normal) | R@1 (Unseen) | R@5 (Unseen) | R@10 (Unseen) |
|---|---|---|---|---|---|---|
| Siam-VGG | 23.3 | - | 52.6 | 10.6 | - | 32.5 |
| HOLEF-VGG | 22.8 | - | 53.1 | 10.9 | - | 33.1 |
| SceneTrilogy | 24.1 | - | 53.9 | - | - | - |
| SceneDiff (w Sketch) | 25.2 | 45.9 | 55.9 | - | - | - |
| FreestyleRet | 29.6 | - | 56.1 | - | - | - |
| Ours | 61.9 | 81.4 | 87.2 | 60.0 | 80.2 | 86.1 |
Performance comparison on FS-COCO dataset
Conclusion
We have shown that a conceptually simple approach, built upon a careful choice of pre-training, encoder architecture, and a debiased contrastive loss, can significantly outperform more complex methods in scene-level SBIR. We believe our method provides a strong, efficient baseline and a clear path forward for future research in cross-modal retrieval.
Citations
If you find our work useful, please consider citing:
@inproceedings{demic2025back,
title={Back To The Drawing Board: Rethinking Scene-Level Sketch-Based Image Retrieval},
author={Demić, Emil and Čehovin Zajc, Luka},
booktitle={British Machine Vision Conference (BMVC2025)},
year={2025}
}